
RAGアプリケーションをRagasで評価する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
まえがき
LLM アプリケーションはいままでのアプリケーションと異なり、ブラックボックスが多く、正しく動き、精度がよくできるか判断、テストすることが難しいです。
たとえば、社内情報をもとに質問に回答する RAG アプリケーションを考えます。
最初はよくあるお問い合わせで質問と想定回答をつくり、精度よい回答ができるか検証しようとしますが、このシンプルな検証が難しいです。
- 連携されたドキュメントで回答をつくるのに十分な情報か(そもそもドキュメントがあるのか)
- 連携されたドキュメントの中で質問回答として使うドキュメントとして適切か(選んだドキュメントは適切か)
- 回答が質問の答えになっているか(回答のフォーマットや、ドキュメントの意図と意味が変わっていないか)
- 回答の文脈に合っているか(チャットでもっと詳しく教えてって返されても適切に検索できているか)
- 古いドキュメントを参考にしていないか(複数のドキュメントがあり、古いバージョンや個人メモに引きづられていないか)
- 想定回答と一致していないけど、AI の回答の方があってるいる可能性
- 想定質問以外の質問で変な回答しないか
- でてきた回答がそれっぽいけど、それ以上でもそれ以下でもなく、具体的な改善点が難しい。
システムを作っている人と、ドキュメントを書いている人が一致していないことが多いため、ドメイン知識不足から回答の良し悪しがわからないことが多いです。
また、プロンプトを改善したら、ある質問・ユースケースでは改悪になったなども発生します。
とりあえず、社内文章を繋いで、インフラができあがり、ユースケースを縦に通せるようになったけど、評価や改善、テストしつづけていくのは難しいです。
アプリケーションの評価ツール Rangs
Rangs は、LLM アプリケーションの評価ツールで、良し悪しをある程度の定量的に測れるのは大変ありがたいです。これがベストというより、発展途上の分野だと思います。
Ragas is a library that provides tools to supercharge the evaluation of Large Language Model (LLM) applications. It is designed to help you evaluate your LLM applications with ease and confidence.
RAG関連のメトリクス
今回は RAG 関連のメトリクスを Rangs を評価していこうと思います。
RAG の仕組みとして、ユーザの質問をして、回答に必要なドキュメントを検索して、LLM に渡して回答を生成します。
評価の仕方は、基本的には、予め想定質問に対する、検索されるべきドキュメント、想定回答を用意し、実施に想定質問から RAG アプリケーションで検索し結果と比較する。
評価する際の登場人物としては、以下の通り。「(検索して/回答に使うべき)、回答に使う根拠にしたドキュメント」が長いので元ネタとした。
- 想定のユーザ質問/指示(プロンプト含む)
- 評価に使う質問。実際にあるよくあるお問い合わせを参考にピックアップ。
- 想定回答
- 一旦人間、実務での回答を正解する。イメージとして、LLM 回答を人間、実務の回答に近づけていく。
- LLM からの回答
- 検査した元ネタとユーザの指示/質問をもとに生成した回答
- 想定の元ネタ
- 回答を作るために使うなら、根拠にすべき正解のドキュメント
- 検索した/ヒットした元ネタ
- 質問に合わせて検索して、ヒットしたドキュメント(一部抜粋を含む)
RAG メトリクスとして、Rangs は 5 つあるみたいです。超意訳で説明します。
どれが何を表しているのか混乱し、いつも読み返してしまうので、イメージで掴むために図と超意訳にしました。
見にくいですが説明だけだと混乱するので、具体例もつけています。
- Context Precision
- 回答に関係する元ネタか
- Context Recall
- 回答に必要な情報を網羅しているか
- Context Entities Recall
- 回答に必要な単語・キーワード(Entity)を網羅しているか
- Faithfulness
- 回答が元ネタを正しく使っているか
- Response Relevancy
- 質問と回答が噛み合っているか
- Noise Sensitivity
- 回答に関係ない元ネタを無視して、回答を作れるか
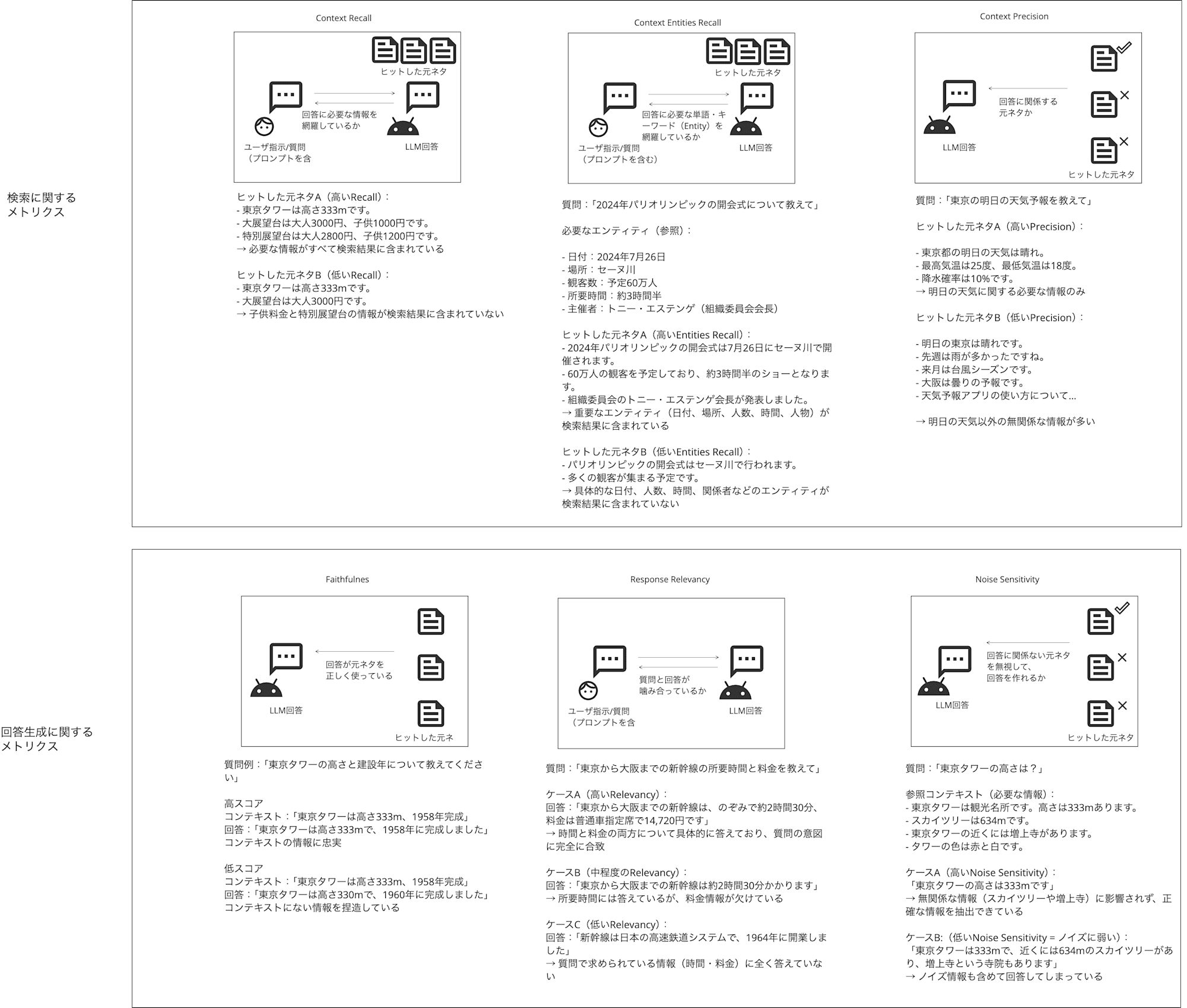
Contextがついてるものは基本的に、質問の回答をつくるために検索してきた元ネタに関するメトリクスで、ドキュメント検索に関する評価。
Response Relevancy と Faithfulness は回答の質、Noise Sensitivity は元ネタにノイズが多くても必要ものだけから答えることができるか堅牢性に関する評価
Ragas のドキュメントには、定義の式やコードまで書かれているので、厳密にはこちら公式ドキュメントや参考文献をご覧ください。
Ragas で実際に測定
面白いのは、評価するのにも LLM を使うので、今回は Bedrock を使うことにします。
LLM の回答を人間や数式で評価するのは感覚にあうけど、LLM が評価するのはなんとも味わい深いです。
uv でアプリケーションを作る
$ mkdir ragas-app
$ cd ragas-app
$ uv init --app
pythonのライブラリーを追加
$ uv add dataset langchain-aws ragas nltk
$ uv sync
Ragas の評価コードする
main.py を以下のようにする。
評価の質問・回答は以下を参考にしました。
また、AWS のクレデンシャルで、Profile を使う場合はこちらを参考にしてください。
from langchain_aws import ChatBedrockConverse
from langchain_aws import BedrockEmbeddings
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import LangchainEmbeddingsWrapper
from ragas.dataset_schema import SingleTurnSample
from ragas import evaluate
from ragas.evaluation import EvaluationDataset
from ragas.metrics import (
ContextPrecision,
ContextRecall,
ContextEntityRecall,
NoiseSensitivity,
ResponseRelevancy,
Faithfulness,
)
bedrock_llm = ChatBedrockConverse(
region_name="us-east-1",
base_url="https://bedrock-runtime.us-east-1.amazonaws.com",
model="anthropic.claude-3-5-sonnet-20240620-v1:0",
temperature=0.4,
)
bedrock_embeddings = BedrockEmbeddings(
region_name="us-east-1",
model_id="amazon.titan-embed-text-v2:0",
)
llm = LangchainLLMWrapper(bedrock_llm)
embeddings = LangchainEmbeddingsWrapper(bedrock_embeddings)
sample = SingleTurnSample(
user_input="What is the Life Insurance Corporation of India (LIC) known for?",
response="The Life Insurance Corporation of India (LIC) is the largest insurance company in India, known for its vast portfolio of investments. LIC contributes to the financial stability of the country.",
reference="The Life Insurance Corporation of India (LIC) is the largest insurance company in India, established in 1956 through the nationalization of the insurance industry. It is known for managing a large portfolio of investments.",
retrieved_contexts=[
"The Life Insurance Corporation of India (LIC) was established in 1956 following the nationalization of the insurance industry in India.",
"LIC is the largest insurance company in India, with a vast network of policyholders and huge investments.",
"As the largest institutional investor in India, LIC manages substantial funds, contributing to the financial stability of the country.",
"The Indian economy is one of the fastest-growing major economies in the world, thanks to sectors like finance, technology, manufacturing etc."
]
)
metrics = [
ContextPrecision(),
ContextRecall(),
ContextEntityRecall(),
NoiseSensitivity(),
ResponseRelevancy(),
Faithfulness(),
]
datasets = EvaluationDataset(samples=[sample])
result = evaluate(datasets, metrics=metrics, llm=llm, embeddings=embeddings)
result.to_pandas().to_csv("output.csv")
Ragas の実行
$ uv run main.py
以下のような csv が output.csv で出力される。
,user_input,retrieved_contexts,response,reference,context_precision,context_recall,context_entity_recall,noise_sensitivity_relevant,answer_relevancy,faithfulness
0,What is the Life Insurance Corporation of India (LIC) known for?,"['The Life Insurance Corporation of India (LIC) was established in 1956 following the nationalization of the insurance industry in India.', 'LIC is the largest insurance company in India, with a vast network of policyholders and huge investments.', 'As the largest institutional investor in India, LIC manages substantial funds, contributing to the financial stability of the country.', 'The Indian economy is one of the fastest-growing major economies in the world, thanks to sectors like finance, technology, manufacturing etc.']","The Life Insurance Corporation of India (LIC) is the largest insurance company in India, known for its vast portfolio of investments. LIC contributes to the financial stability of the country.","The Life Insurance Corporation of India (LIC) is the largest insurance company in India, established in 1956 through the nationalization of the insurance industry. It is known for managing a large portfolio of investments.",0.9999999999666667,1.0,0.9999999975,0.3333333333333333,0.7841645641561451,1.0
,
まとめ
RAG の評価をある程度定量的にはかせるのはとても便利ですが、実務に落とし込むのもまた難しいです。
- すべてのドキュメントを把握して、ベストな理想回答を作れる人はいない
- 質問に対する、完璧な回答/要素を網羅してると言い切ることは難しい
- 評価セット用の質問以外で、実際の質問ベースに評価すると、質問が自体適当すぎる(回答するのに必要な情報が含まれていなく、人間が見ても回答が難しい)
- 正解かどうかの線引き・基準が決められていなかったり、要件や温度感・個人の感覚によって異なる
私としては、プロジェクトの評価につかうといより、プロジェクトの健康診断のような使い方がマッチしていると考えています。
想定質問/想定回答を修正に度に CI で回して、変更したことによるデグレや回答が著しく下がっていないか、モデルよって回答が大きく変わっていないか前の状態から変化をみていくのがいいのかなと思いました。










